👋 About me [Updated 25/11/2025]
My name is Junhao Cheng (程钧豪). I received my bachelor's degree from Sun Yat-sen University (SYSU) in , supervised by Prof. Xiaodan Liang (梁小丹). Now I am an MPhil student at Prof. Jing Liao (廖菁)'s lab. Before this, I had the privilege of interning in Prof. Ming-Hsuan Yang's lab and working closely with him.
I am currently a research intern at Kuaishou Kling team. My research interests lie in Interactive AI. Now I focus on foundation models and novel applications for image/video understanding and generation.
I am open to research collaborations, PhD opportunities (27 Fall), and industry/startup roles. If you're interested in discussing potential synergies, I'd be happy to 📧connect.
🔥 News
2025.11:
Release Video-as-Answer, extending next-event prediction to video answer.
2025.06:
🎉🎉 One paper is accepted by ICCV 2025.
2025.06:
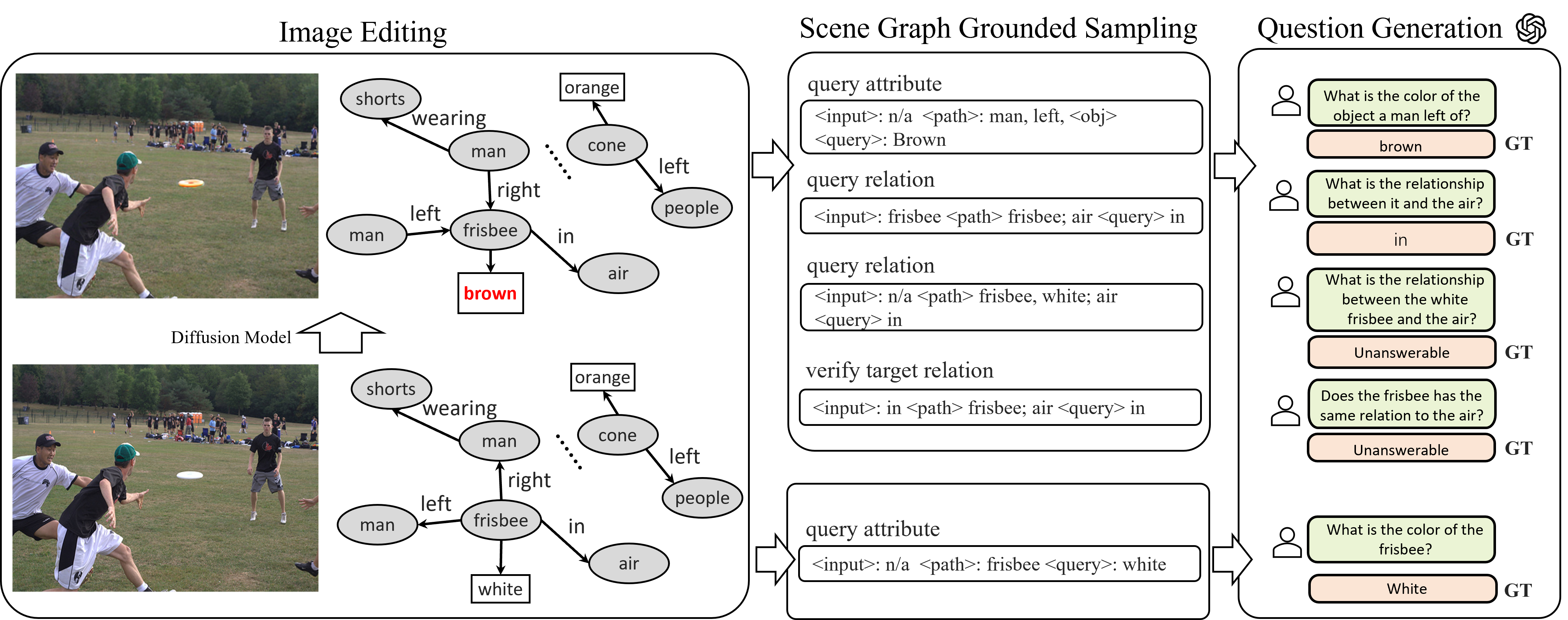
Release Video-Holmes, evaluating MLLMs for complex video reasoning.
2025.04:
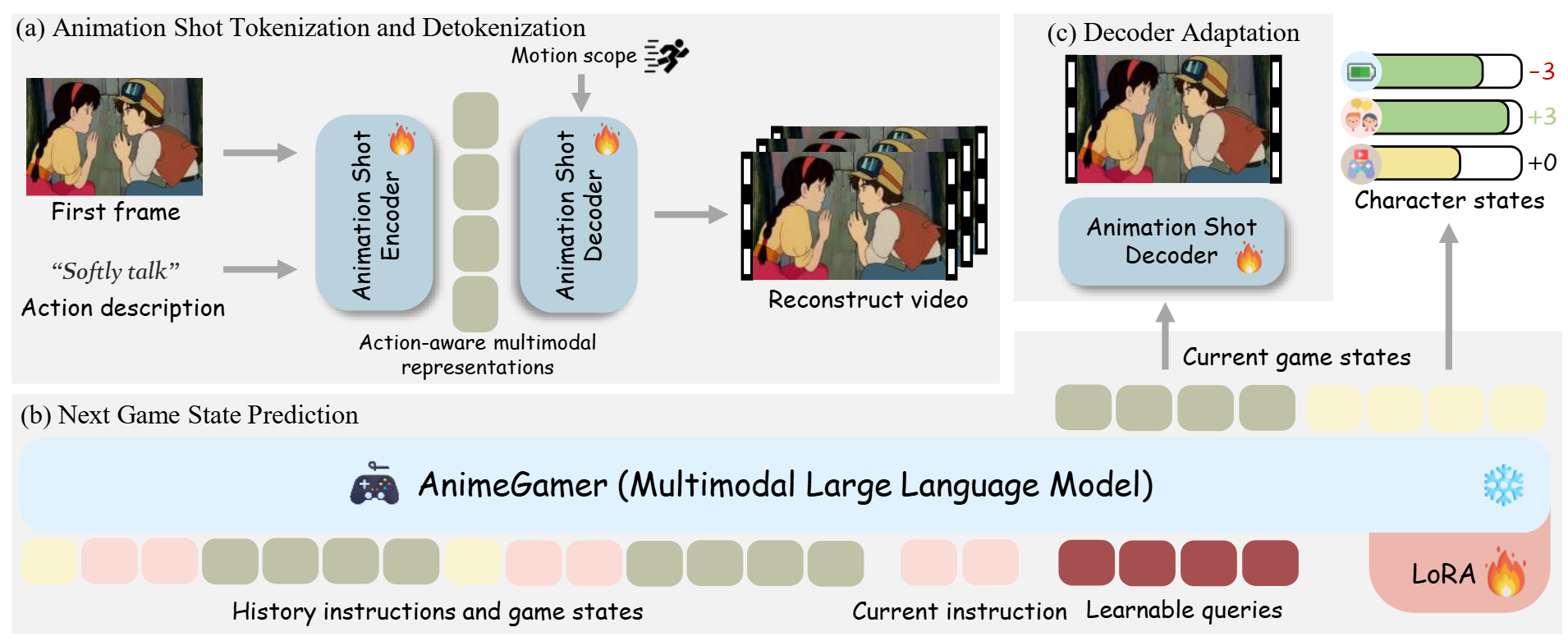
Release AnimeGamer (300+Stars✨), transforming characters from anime films into interactive entities with an MLLM.
2024.06:
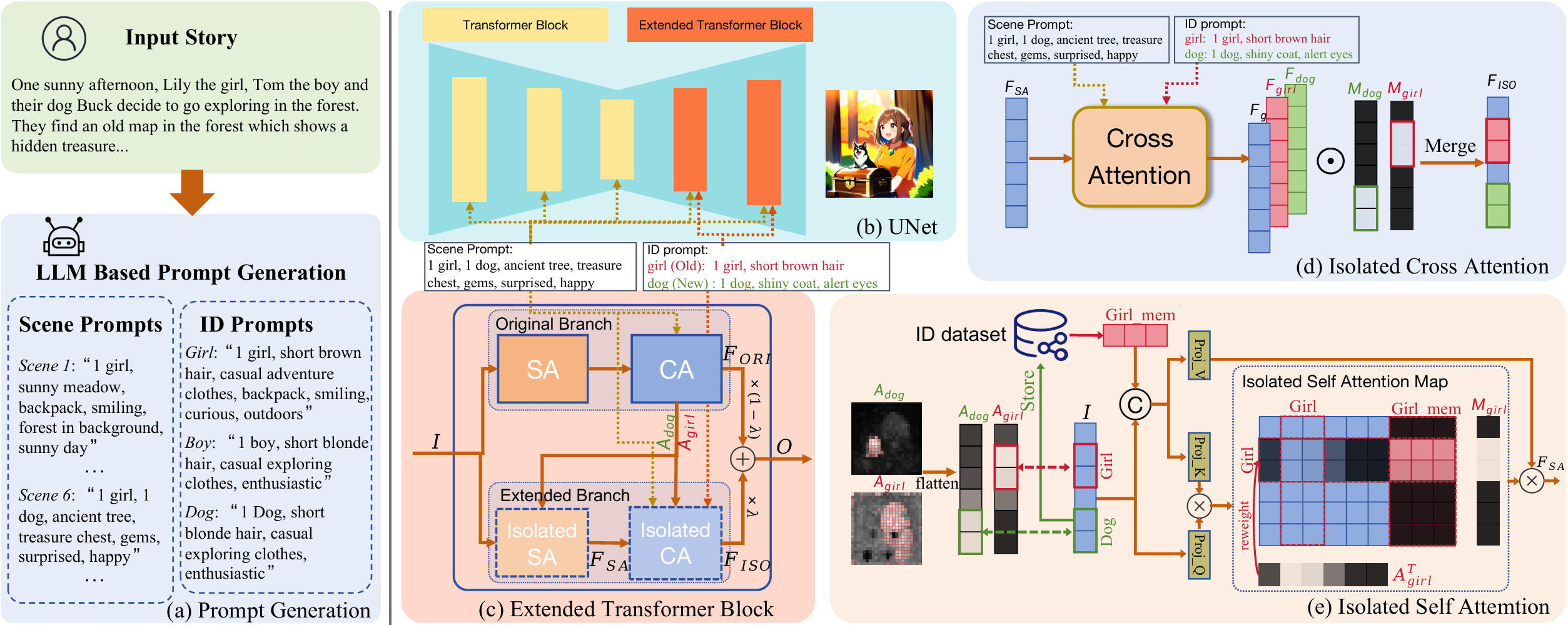
Release AutoStudio (400+Stars✨), generating comic book with multi-character, multi-turn consistency.
2024.05:
🎉🎉 One paper is accepted by ACL 2024.
🎓 Educations


💻 Internships



Research Intern @ Lenovo, Research Institute
2023.09 - 2024.08